最近由于某些原因,需要用到Python模拟登录网站,但是以前对这块并不了解,而且目标网站的登录方法较为复杂, 所以一下卡在这里了,于是我决定从简单的模拟开始,逐渐深入地研究下这块。
登录特点:明文传输,有特殊标志数据
会话对象requests.Session能够跨请求地保持某些参数,比如cookies,即在同一个Session实例发出的所有请求都保持同一个cookies,而requests模块每次会自动处理cookies,这样就很方便地处理登录时的cookies问题。在cookies的处理上会话对象一句话可以顶过好几句urllib模块下的操作。即相当于urllib中的:
1 | cj = http.cookiejar.CookieJar() |
模拟登录V站
本篇文章的任务是利用request.Session模拟登录V2EX( http://www.v2ex.com/ )这个网站,即V站。
工具: Python 3.5,BeautifulSoup模块,requests模块,Chrome
这个网站登录的时候抓到的数据如下: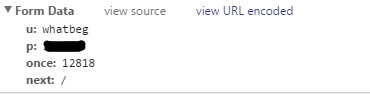
其中用户名(u)、密码(p)都是明文传输的,很方便。once的话从分析登录URL: http://www.v2ex.com/signin 的源文件(下图)可以看出,应该是每次登录的特有数据,我们需要提前把它抓出来再放到Form Data里面POST给网站。
抓出来还是老方法,用BeautifulSoup神器即可。这里又学到一种抓标签里面元素的方法,比如抓上面的”value”,用soup.find('input',{'name':'once'})['value']即可
即抓取含有name=”once”的input标签中的value对应的值。
于是构建postData,然后POST。
怎么显示登录成功呢?这里通过访问 http://www.v2ex.com/settings 即可,因为这个网址没有登录是看不了的: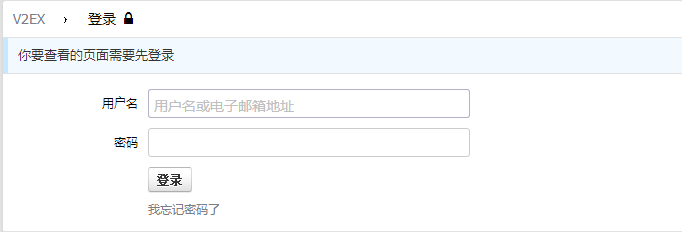
经过上面的分析,写出源代码(参考了alexkh的代码):
1 | import requests |
然后运行发现成功登录:
上面趴下来的网页源代码即为http://www.v2ex.com/settings 的代码。这里once为91279.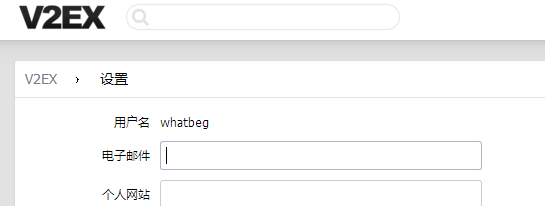
至此,登录成功。