本篇主要讲解 Item 类封装数据以及 ItemLoader 加载数据机制。
一. 创建 Item 类
为了将网页解析后获取的数据进行格式化,便于数据的传递与进一步的操作,Scrapy 提供了 Item 类来对数据进行封装。
要使用 Item 类非常简单,直接继承 scrapy 的 Item 类即可,然后可以定义相应的属性字段来对数据进行存储,其字段类型为 scrapy.Field()。 Scrapy 只提供了 Field() 一种字段类型,可以用来存储任意类型的数据。
现在我们根据上一节解析到的 StackoverFlow 的问题来创建我们的 Item 类,代码如下:
1 | class StackQuestionItem(scrapy.Item): |
创建完成后就可以在 parse 方法中将解析到的数据进行封装了, 结合上一篇文章中的解析代码如下:
1 | def parse_by_css(self, response): |
生成的 Item 类通过 yield 返回时,Scrapy 会根据 settings 文件中的配置来传输到对应的 pipeline 类中,其默认已经给我们创建好了一个 pipeline 类,配置文件如下:
1 | class StackoverflowspiderPipeline: |
上面就是默认生成的 pipeline 类,可以看到自动生成了一个 process_item() 方法来处理传递过来的 Item,关于 pipeline 的内容后面会专门介绍,Item 类的基本使用就像上面这样,非常简单,下面我们看下其 ItemLoader 机制。
二. 使用 ItemLoader 解析数据
通过之前的学习,已经知道网页的基本解析流程就是先通过 css/xpath 方法进行解析,然后再把值封装到 Item 中,如果有特殊需要的话还要对解析到的数据进行转换处理,这样当解析代码或者数据转换要求过多的时候,会导致代码量变得极为庞大,从而降低了可维护性。同时在 sipider 中编写过多的数据处理代码某种程度上也违背了单一职责的代码设计原则。我们需要使用一种更加简洁的方式来获取与处理网页数据,ItemLoader 就是用来完成这件事情的。
ItemLoader 类位于 scrapy.loader ,它可以接收一个 Item 实例来指定要加载的 Item, 然后指定 response 或者 selector 来确定要解析的内容,最后提供了 add_css()、 add_xpath() 方法来对通过 css 、 xpath 解析赋值,还有 add_value() 方法来单独进行赋值。
示例代码如下:
1 | from scrapy.loader import ItemLoader |
上面就是简要的示例代码,可以看到相比之前的解析,赋值和解析代码合并在了一起,爬虫文件中的代码量减少了一半。当解析的数据很多而且还需要进行特殊转换比如通过正则进行匹配替换的时候其效果更佳的明显。
上面代码解析完成后生成的都是一个 list,其值如下: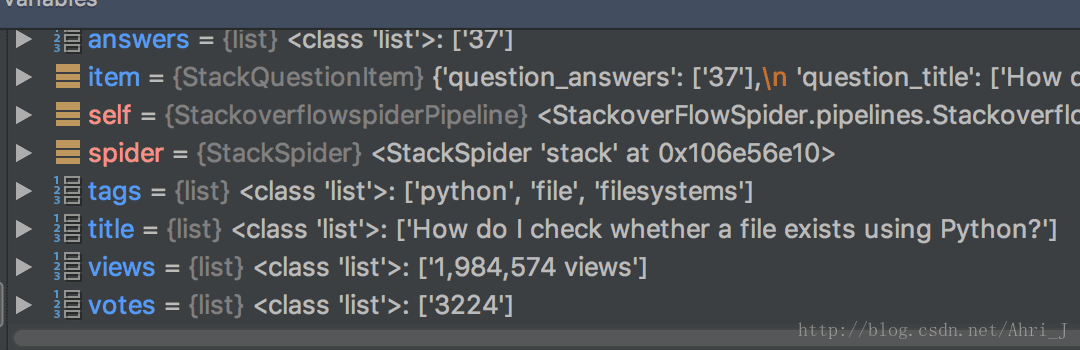
可以看到无论解析出来的值的数量是多少,ItemLoader 默认都会返回一个 list。在之前的方式中我们都是通过 extract_first() 获取第一个值或者通过 extract() 解析到值后进行遍历的。在 ItemLoader 中,为我们提供了 processor 来对数据进行处理。
在 ItemLoader 类中,提供了 default_output_processor 和 default_input_processor 来对数据的输入与输出进行解析,如果我们需要只获取解析后的第一个值,可以指定 default_output_processor 为 TakeFirst() 即可,这是 Scrapy 提供的一个解析处理类,用来获取第一个元素,代码如下:
1 | class DefaultItemLoader(ItemLoader): |
完成自定义的 ItemLoader 类之后就可以在 parse 中使用了
1 | item_loader = DefaultItemLoader(item=StackQuestionItem(), selector=question) |
上面的代码使用了自定义的 DefaultItemLoader,因为会获取到 list 中的第一个值,但是对于 tags 而言我们要的是 list 而不是通用的获取的第一个值,对于这种特殊的处理情况,就需要在 Item 类中进行设置了。
Scrapy 允许我们在声明 Item 类定义其字段时,为每一个字段设置单独的数据处理方法,代码如下:
1 | from scrapy.loader.processors import MapCompose, TakeFirst, Join |
可以看到,我们可以在字段定义时想 scrapy.Field() 中指定 input_processor 和 output_processor 两个参数来指定对数据的处理。
scrapy 提供 的 MapCompose 方法允许我们指定一系列的处理方法,Scrapy 会将 解析到的 list 中的值依次传递到每个方法中对值进行处理,这里我们在 title 前面加了 Question: 前缀。然后在 tags 中通过 Join() 设置了分隔符来连接每一个 tag。解析后获取到的结果如下: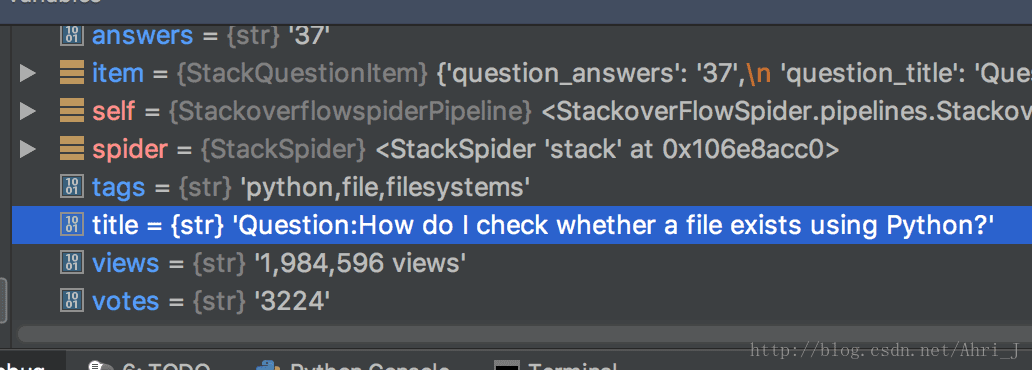
可以看到 tag 已经使用逗号分隔符连接起来了,title 前面也加上了 Question: 前缀。
关于更多的处理方法可以参阅官方文档,在Field定义中声明输入/输出处理器
最后在总结一下操作过程,首先定义一个 ItemLoader 类同时指定通用的 input/output 处理方法,然后在 parse 方法中声明 ItemLoader ,传递 Item 实例 和 response/selector。 通过 ItemLoader 的 add_css/add_xpath/add_value 来进行赋值。
如果对数据有特殊的处理,就在 Item 类的 Field 中传递 input_processor 和 output_processor 来指定处理函数,来完成整个数据的解析和处理。
关于 ItemLoader 的说明就到这里了,更加详细的操作可以参阅官方文档。接下来就是讲 Item 实例传递到 pipeline 进行处理了。下一篇将简要介绍 Pipeline 的使用,包括 Scrapy 提供的常用 Pipeline 类以及自定义 Pipeline 类。