Puppeteer 是 Chrome 开发团队在 2017 年发布的一个 Node.js 包,用来模拟 Chrome 浏览器的运行。我们团队从 Puppeteer 刚发布出来就开始成为忠实用户了(主要是因为 PhantomJs 坑太多了),本文主要在介绍 Puppeteer 的同时,结合我们平时的实践做一个分享。
学习 Puppeteer 之前我们先来了解一下 Chrome DevTool Protocol
什么是 Chrome DevTool Protocol
- CDP 基于 WebSocket,利用 WebSocket 实现与浏览器内核的快速数据通道
- CDP 分为多个域(DOM,Debugger,Network,Profiler,Console…),每个域中都定义了相关的命令和事件(Commands and Events)
- 我们可以基于 CDP 封装一些工具对 Chrome 浏览器进行调试及分析,比如我们常用的 “Chrome 开发者工具” 就是基于 CDP 实现的
- 如果你以 remote-debugging-port 参数启动 Chrome,那么就可以看到所有 Tab 页面的开发者调试前端页面,还会在同一端口上还提供了 http 服务,主要提供以下几个接口:
1 | GET /json/version # 获取浏览器的一些元信息 |
- 很多有用的工具都是基于 CDP 实现的,比如 Chrome 开发者工具,chrome-remote-interface,Puppeteer 等
什么是 Headless Chrome
- 在无界面的环境中运行 Chrome
- 通过命令行或者程序语言操作 Chrome
- 无需人的干预,运行更稳定
- 在启动 Chrome 时添加参数 --headless,便可以 headless 模式启动 Chrome
1 | alias chrome="/Applications/Google\ Chrome.app/Contents/MacOS/Google\ Chrome" # Mac OS X 命令别名 |
- chrome 启动时可以加一些什么参数,大家可以点击这里查看
Puppeteer 是什么
- Puppeteer 是 Node.js 工具引擎
- Puppeteer 提供了一系列 API,通过 Chrome DevTools Protocol 协议控制 Chromium/Chrome 浏览器的行为
- Puppeteer 默认情况下是以 headless 启动 Chrome 的,也可以通过参数控制启动有界面的 Chrome
- Puppeteer 默认绑定最新的 Chromium 版本,也可以自己设置不同版本的绑定
- Puppeteer 让我们不需要了解太多的底层 CDP 协议实现与浏览器的通信
Puppeteer 能做什么
官方称:“Most things that you can do manually in the browser can be done using Puppeteer”,那么具体可以做些什么呢?
- 网页截图或者生成 PDF
- 爬取 SPA 或 SSR 网站
- UI 自动化测试,模拟表单提交,键盘输入,点击等行为
- 捕获网站的时间线,帮助诊断性能问题
- 创建一个最新的自动化测试环境,使用最新的 js 和最新的 Chrome 浏览器运行测试用例
- 测试 Chrome 扩展程序
- …
Puppeteer API 分层结构
Puppeteer 中的 API 分层结构基本和浏览器保持一致,下面对常使用到的几个类介绍一下:
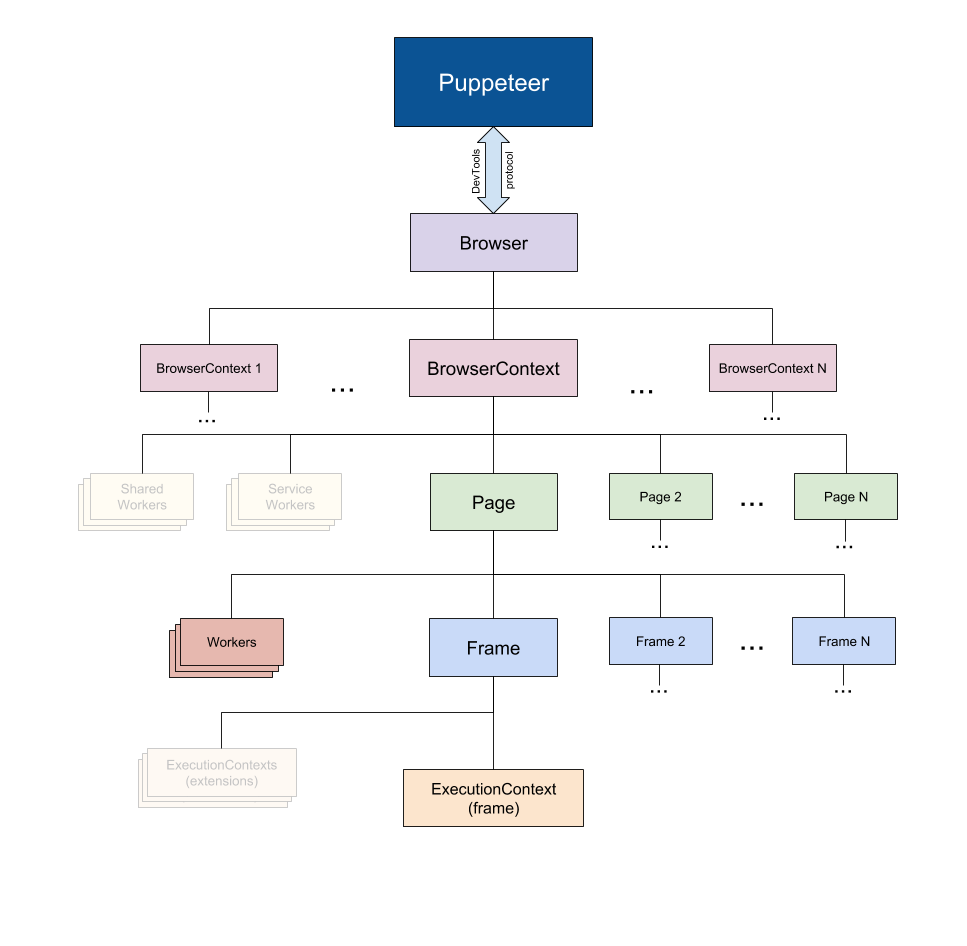
- Browser: 对应一个浏览器实例,一个 Browser 可以包含多个 BrowserContext
- BrowserContext: 对应浏览器一个上下文会话,就像我们打开一个普通的 Chrome 之后又打开一个隐身模式的浏览器一样,BrowserContext 具有独立的 Session(cookie 和 cache 独立不共享),一个 BrowserContext 可以包含多个 Page
- Page:表示一个 Tab 页面,通过 browserContext.newPage()/browser.newPage() 创建,browser.newPage() 创建页面时会使用默认的 BrowserContext,一个 Page 可以包含多个 Frame
- Frame: 一个框架,每个页面有一个主框架(page.MainFrame()),也可以多个子框架,主要由 iframe 标签创建产生的
- ExecutionContext: 是 javascript 的执行环境,每一个 Frame 都一个默认的 javascript 执行环境
- ElementHandle: 对应 DOM 的一个元素节点,通过该该实例可以实现对元素的点击,填写表单等行为,我们可以通过选择器,xPath 等来获取对应的元素
- JsHandle:对应 DOM 中的 javascript 对象,ElementHandle 继承于 JsHandle,由于我们无法直接操作 DOM 中对象,所以封装成 JsHandle 来实现相关功能
- CDPSession:可以直接与原生的 CDP 进行通信,通过 session.send 函数直接发消息,通过 session.on 接收消息,可以实现 Puppeteer API 中没有涉及的功能
- Coverage:获取 JavaScript 和 CSS 代码覆盖率
- Tracing:抓取性能数据进行分析
- Response: 页面收到的响应
- Request: 页面发出的请求
如何创建一个 Browser 实例
puppeteer 提供了两种方法用于创建一个 Browser 实例:
-
puppeteer.connect: 连接一个已经存在的 Chrome 实例 -
puppeteer.launch: 每次都启动一个 Chrome 实例
1 | const puppeteer = require('puppeteer'); |
这两种方式的对比:
-
puppeteer.launch每次都要重新启动一个 Chrome 进程,启动平均耗时 100 到 150 ms,性能欠佳 -
puppeteer.connect可以实现对于同一个 Chrome 实例的共用,减少启动关闭浏览器的时间消耗 -
puppeteer.launch启动时参数可以动态修改 - 通过
puppeteer.connect我们可以远程连接一个 Chrome 实例,部署在不同的机器上 -
puppeteer.connect多个页面共用一个 chrome 实例,偶尔会出现 Page Crash 现象,需要进行并发控制,并定时重启 Chrome 实例
如何等待加载?
在实践中我们经常会遇到如何判断一个页面加载完成了,什么时机去截图,什么时机去点击某个按钮等问题,那我们到底如何去等待加载呢?
下面我们把等待加载的 API 分为三类进行介绍:
加载导航页面
-
page.goto:打开新页面 -
page.goBack:回退到上一个页面 -
page.goForward:前进到下一个页面 -
page.reload:重新加载页面 -
page.waitForNavigation:等待页面跳转
Pupeeteer 中的基本上所有的操作都是异步的,以上几个 API 都涉及到关于打开一个页面,什么情况下才能判断这个函数执行完毕呢,这些函数都提供了两个参数 waitUtil 和 timeout,waitUtil 表示直到什么出现就算执行完毕,timeout 表示如果超过这个时间还没有结束就抛出异常。
1 | await page.goto('https://www.baidu.com', { |
以上 waitUtil 有四个事件,业务可以根据需求来设置其中一个或者多个触发才以为结束,networkidle0 和 networkidle2 中的 500ms 对时间性能要求高的用户来说,还是有点长的
等待元素、请求、响应
-
page.waitForXPath:等待 xPath 对应的元素出现,返回对应的 ElementHandle 实例 -
page.waitForSelector:等待选择器对应的元素出现,返回对应的 ElementHandle 实例 -
page.waitForResponse:等待某个响应结束,返回 Response 实例 -
page.waitForRequest:等待某个请求出现,返回 Request 实例
1 | await page.waitForXPath('//img'); |
自定义等待
如果上面提供的等待方式都不能满足我们的需求,puppeteer 还提供我们提供两个函数:
-
page.waitForFunction:等待在页面中自定义函数的执行结果,返回 JsHandle 实例 -
page.waitFor:设置等待时间,实在没办法的做法
1 | await page.goto(url, { |
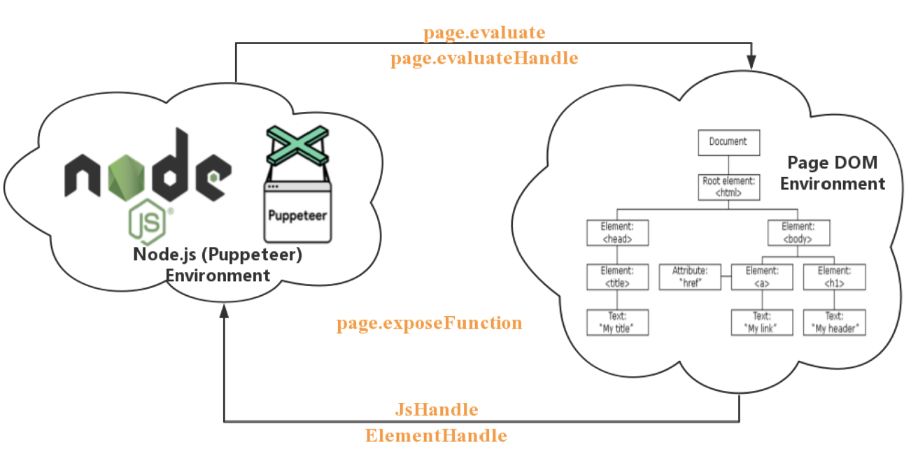
两个独立的环境
在使用 Puppeteer 时我们几乎一定会遇到在这两个环境之间交换数据:运行 Puppeteer 的 Node.js 环境和 Puppeteer 操作的页面 Page DOM,理解这两个环境很重要
- 首先 Puppeteer 提供了很多有用的函数去 Page DOM Environment 中执行代码,这个后面会介绍到
- 其次 Puppeteer 提供了 ElementHandle 和 JsHandle 将 Page DOM Environment 中元素和对象封装成对应的 Node.js 对象,这样可以直接这些对象的封装函数进行操作 Page DOM
10 个用例告诉你如何使用 puppeteer
下面介绍 10 个关于使用 Puppeteer 的用例,并在介绍用例的时候会穿插的讲解一些 API,告诉大家如何使用 Puppeteer:
Case1:截图
我们使用 Puppeteer 既可以对某个页面进行截图,也可以对页面中的某个元素进行截图:
1 | (async () => { |
我们怎么去获取页面中的某个元素呢?
-
page.$('#uniqueId'):获取某个选择器对应的第一个元素 -
page.$$('div'):获取某个选择器对应的所有元素 -
page.$x('//img'):获取某个 xPath 对应的所有元素 -
page.waitForXPath('//img'):等待某个 xPath 对应的元素出现 -
page.waitForSelector('#uniqueId'):等待某个选择器对应的元素出现
case2: 模拟用户登录
1 | (async () => { |
那么 ElementHandle 都提供了哪些操作元素的函数呢?
-
elementHandle.click():点击某个元素 -
elementHandle.tap():模拟手指触摸点击 -
elementHandle.focus():聚焦到某个元素 -
elementHandle.hover():鼠标 hover 到某个元素上 -
elementHandle.type('hello'):在输入框输入文本
case3:请求拦截
请求在有些场景下很有必要,拦截一下没必要的请求提高性能,我们可以在监听 Page 的 request 事件,并进行请求拦截,前提是要开启请求拦截 page.setRequestInterception(true)。
1 | (async () => { |
那 page 页面上都提供了哪些事件呢?
-
page.on('close')页面关闭 -
page.on('console')console API 被调用 -
page.on('error')页面出错 -
page.on('load')页面加载完 -
page.on('request')收到请求 -
page.on('requestfailed')请求失败 -
page.on('requestfinished')请求成功 -
page.on('response')收到响应 -
page.on('workercreated')创建 webWorker -
page.on('workerdestroyed')销毁 webWorker
case4:获取 WebSocket 响应
Puppeteer 目前没有提供原生的用于处理 WebSocket 的 API 接口,但是我们可以通过更底层的 Chrome DevTool Protocol (CDP) 协议获得
1 | (async () => { |
case5:植入 javascript 代码
Puppeteer 最强大的功能是,你可以在浏览器里执行任何你想要运行的 javascript 代码,下面是我在爬 188 邮箱的收件箱用户列表时,发现每次打开收件箱再关掉都会多处一个 iframe 来,随着打开收件箱的增多,iframe 增多到浏览器卡到无法运行,所以我在爬虫代码里加了删除无用 iframe 的脚本:
1 | (async () => { |
有哪些函数可以在浏览器环境中执行代码呢?
-
page.evaluate(pageFunction[, ...args]):在浏览器环境中执行函数 -
page.evaluateHandle(pageFunction[, ...args]):在浏览器环境中执行函数,返回 JsHandle 对象 -
page.$$eval(selector, pageFunction[, ...args]):把 selector 对应的所有元素传入到函数并在浏览器环境执行 -
page.$eval(selector, pageFunction[, ...args]):把 selector 对应的第一个元素传入到函数在浏览器环境执行 -
page.evaluateOnNewDocument(pageFunction[, ...args]):创建一个新的 Document 时在浏览器环境中执行,会在页面所有脚本执行之前执行 -
page.exposeFunction(name, puppeteerFunction):在 window 对象上注册一个函数,这个函数在 Node 环境中执行,有机会在浏览器环境中调用 Node.js 相关函数库
case6: 如何抓取 iframe 中的元素
一个 Frame 包含了一个执行上下文(Execution Context),我们不能跨 Frame 执行函数,一个页面中可以有多个 Frame,主要是通过 iframe 标签嵌入的生成的。其中在页面上的大部分函数其实是 page.mainFrame().xx 的一个简写,Frame 是树状结构,我们可以通过 frame.childFrames() 遍历到所有的 Frame,如果想在其它 Frame 中执行函数必须获取到对应的 Frame 才能进行相应的处理
以下是在登录 188 邮箱时,其登录窗口其实是嵌入的一个 iframe,以下代码时我们在获取 iframe 并进行登录
1 | (async () => { |
case7: 页面性能分析
Puppeteer 提供了对页面性能分析的工具,目前功能还是比较弱的,只能获取到一个页面性能执行的数据,如何分析需要我们自己根据数据进行分析,据说在 2.0 版本会做大的改版:
- 一个浏览器同一时间只能 trace 一次
- 在 devTools 的 Performance 可以上传对应的 json 文件并查看分析结果
- 我们可以写脚本来解析 trace.json 中的数据做自动化分析
- 通过 tracing 我们获取页面加载速度以及脚本的执行性能
1 | (async () => { |
case8: 文件的上传和下载
在自动化测试中,经常会遇到对于文件的上传和下载的需求,那么在 Puppeteer 中如何实现呢?
1 | (async () => { |
case9:跳转新 tab 页处理
在点击一个按钮跳转到新的 Tab 页时会新开一个页面,这个时候我们如何获取改页面对应的 Page 实例呢?可以通过监听 Browser 上的 targetcreated 事件来实现,表示有新的页面创建:
1 | let page = await browser.newPage(); |
case10: 模拟不同的设备
Puppeteer 提供了模拟不同设备的功能,其中 puppeteer.devices 对象上定义很多设备的配置信息,这些配置信息主要包含 viewport 和 userAgent,然后通过函数 page.emulate 实现不同设备的模拟
1 | const puppeteer = require('puppeteer'); |
Puppeteer vs Phantomjs
- 完全真实的浏览器操作,支持所有 Chrome 特性
- 可以提供不同版本的 Chrome 浏览器环境
- Chrome 团队维护,拥有更好的兼容性和前景
- headless 参数动态配置,调试更为方便,通过 –remote-debugging-port=9222,可以进入调试界面调试
- 支持最新的 JS 语法,比如 async/await 等
- 完备的事件驱动机制,不需要太多的 sleep
- Phantomjs 环境安装复杂,API 调用不友好
- 两者的主要不同在于 Phantomjs 使用了一个较老版本的 WebKit 作为它的渲染引擎
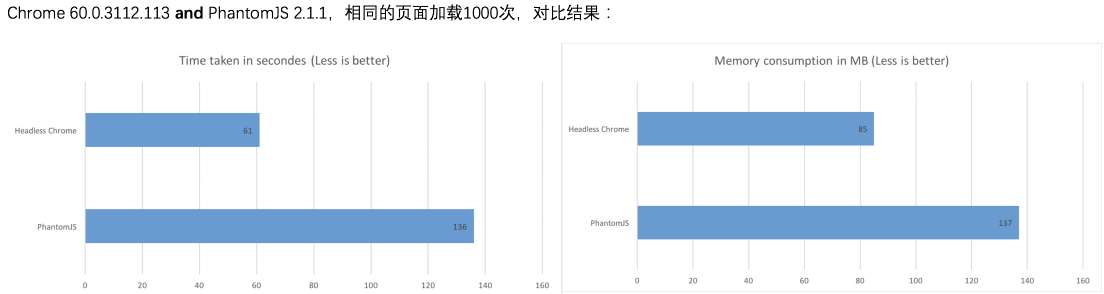
- 比 Phantomjs 有更快更好的性能,以下是其他人对于 Puppeteer 和 Phantomjs 性能对比结果:
Headless Chrome vs PhantomJS Benchmark
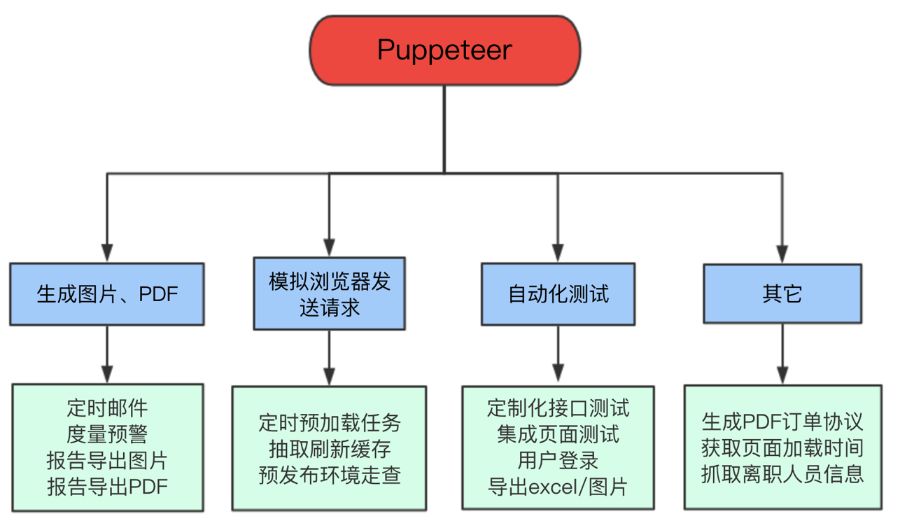
Puppeteer 在我们团队的应用场景
性能和优化
- 关于共享内存:
1 | Chrome 默认使用 /dev/shm 共享内存,但是 docker 默认/dev/shm 只有64MB,显然是不够使用的,提供两种方式来解决: |
- 尽量使用同一个浏览器实例,这样可以实现缓存共用
- 通过请求拦截没必要加载的资源
- 像我们自己打开 Chrome 一样,tab 页多必然会卡,所以必须有效控制 tab 页个数
- 一个 Chrome 实例启动时间长了难免会出现内存泄漏,页面奔溃等现象,所以定时重启 Chrome 实例是有必要的
- 为了加快性能,关闭没必要的配置,比如:-no-sandbox(沙箱功能),--disable-extensions(扩展程序)等
- 尽量避免使用 page.waifFor(1000),让程序自己决定效果会更好
- 因为和 Chrome 实例连接时使用的 Websocket,会存在 Websocket sticky session 问题,这个需要特别注意