将用两篇文章简要的介绍一下Backtrader这个库。
第一篇代码部分涉及的较少,主要讲讲Backtrader的优势以及整体框架。
第二篇会讲如何在Backtrader中进行回测、选股、优化及可视化,并给出例子中的源码。
后续个人也会尝试结合券商金融工程的研报进行一些有趣的研究。
0.引言
对于绝大多数使用Python回测交易策略的研究人员,通常有以下三个选项:
1)使用现成的较成熟的库回测
2)构建自己的回测平台
3)使用云交易平台
这里主要讨论第一个选项。其优点是可以快速的测试策略,优化参数,同时将所有数据都安全地存储在本地计算机上。( 如果当前可用的解决方案不能满足需求,则可以考虑选项2实现个性化的需求)
目前两个比较流行的本地回测库是Backtrader和Zipline,本文将重点介绍Backtrader这个库。
1.什么是Backtrader?
Backtrader是一个帮助金融市场交易者进行策略开发和测试的开源Python库。在Backtrader的开源框架中,允许用户基于历史数据对策略进行测试与优化,对计算结果进行可视化,甚至可用于实时交易。
2.为什么学习Backtrader?
Backtrader可大大节省量化研究人员在Coding上所花时间,从而专注于开发、测试及优化市场策略。在庞大的社区和活跃的论坛中,可轻松地找到使用时遇到问题的解决方案。此外,Backtrader网站上的大量文档甚至可能让你发现你策略中的关键部分。
Backtrader的常见优点如下:
回测测试
成熟的回测程序减少了清理数据并进行迭代等策略测试中所必须的繁琐过程。它具有可用于各种数据源的内置函数,保证数据导入更加容易。优化
策略参数的调整有时可能带来同类策略是否盈利的差别。运行回测后,只需更改几行代码即可轻松完成优化。绘图
Python的绘图工具并不是十分友好,尤其是第一次使用时。在Backtrader中可用少量代码创建复杂的图表。技术指标
大多数主流指标已在Backtrader平台中实现。用户若想测试某个指标,但不确定其效果如何,可以尝试使用少量代码在Backtrader中对其进行测试,避免花费大量时间在弄清指标含义及编程实现上。对复杂策略的支持
想要从一个数据集中获取信号并在另一个数据集上执行交易?策略是否涉及多个时间范围?还是需要重新采样数据?针对这些情形,Backtrader考虑到了市场不同的交易方式,并提供了广泛的支持。开源
- 使用者拥有对所有单个组件的完全访问权限,并且可以根据需要对他们进行改写。
- 无需将策略上传到第三方服务器,保证了策略的私密性。
- 没有义务升级和处理不必要的更改,就像使用公司的软件一样。一个反面案例是几年前Quantopian停止了实盘交易。它迫使许多用户迁移到另一个可能很麻烦的平台。
研发积极
这可能是Backtrader尤其突出的领域。该框架最初于2015年开发,此后不断进行改进。就在几周前,基于Pandas的技术分析库已发布,以解决流行且常用的TA-Lib框架中的问题。此外,由于拥有广泛的用户基础,因此也拥有大量积极的第三方开发者。实时交易
如果对回测结果感到满意,则可以轻松迁移到Backtrader中的实时环境。如果打算使用平台提供的内置指标,则此功能特别有用。
3.阻碍学习Backtrader的原因
潜在的陡峭学习曲线
Backtrader可以做很多事情,它非常全面。但是附加功能可以看作是一把双刃剑,需要花费不少时间了解所使用的语法和逻辑。对库本身的深入理解
在上一点的基础上,最好浏览任何库的源代码以更好地了解框架。源代码中包含了多达470个项目。尽管其中一些是示例或数据集和一些不再使用的脚本,然而还是有很多事情要做。创建私人的框架
有些人倾向于完全掌握自己的软件,宁愿自己耗费不小的精力创建一个回测平台。在大多数情况下,这带来巨大工作量,但有明显的好处。如果只是想了解一个简单策略的大体概念,尝试遍历过往数据而不是学习库可能会更容易。
4.Backtrader的工作原理
通过对过去的价格数据进行回溯测试,分析策略在过往市场中的表现。
Backtrader库的基本功能如下:
- 遍历历史数据,根据策略给出的信号来模拟交易的执行。它以多种方式扩展了此功能。
- “Analyzer”可提供评估策略优劣的统计信息。在本教程的稍后部分的优化测试中,我们将使用常用的夏普比率展示一个示例。
- 在优化方面,内置优化模块使用多进程技术,充分利用CPU的多核特性加快处理速度。
- 基于matplotlib库在回测结束时创建图表,提供直观的分析图。
5.Backtrader的安装
最简单方法是通过命令行 pip install backtrader。
如果计划使用图表功能,则应安装matplotlib(最低版本要求是1.4.1)。可以通过从命令行输入pip Frozen以显示已安装的Python软件包来确认它已安装在系统上。如果需要安装,可以通过pip install backtrader [plotting]或pip install matplotlib进行安装。
或者,可以从源代码运行Backtrader。从Backtrader GitHub页面下载zip文件 并将backtrader目录放置在项目文件中。
6.IDE的选择
在深入研究代码之前,让我们花一点时间来讨论IDE。IDE或集成开发环境只是一个用于从中编写和调试代码的编辑器。
有几种流行的IDE,选择合适的IDE通常取决于个人喜好。Python随附有一个称为IDLE的IDE。其中一些受欢迎的第三方Python IDE包括VS Code,Sublime Text,PyCharm和Spyder。
另一个考虑因素是是否使用交互式IDE。交互式IDE的一个流行选择是Jupyter Notebook。
交互式IDE具有执行选定代码块而无需运行整个脚本的附加功能。在测试新库时,这非常有用,因为可以尝试其他功能,而不必注释掉或删除先前的代码块。
虽然可以在Backtrader中使用交互式IDE的某些功能,但不建议这样做。某些功能(例如优化)需要进行多重处理,而这些功能不适用于交互式IDE。如果决定使用交互式IDE,则应该能够继续学习本教程直到优化部分为止。
7.Backtrader的基本配置
基本的Backtrader脚本有两个主要组件,Strategy类和Cerebro引擎。
1 | import backtrader as bt |
在下面的示例中,我们将更详细地讨论Strategy类。Strategy类中包含了确定和执行交易信号的所有逻辑。用户还可以在其中创建或调用指标,并确定要记录或打印的内容。
Cerebro引擎是Backtrader的核心。在调用cerebro.run()命令之前,我们将向其添加数据和策略。
8.Backtrader的数据导入
有几种获取数据的方法。比如券商开放的历史数据和实时行情API访问权限。另外,也有第三方API可供下载历史数据。下面从Yahoo Finance网站下载CSV格式的数据为例进行介绍。
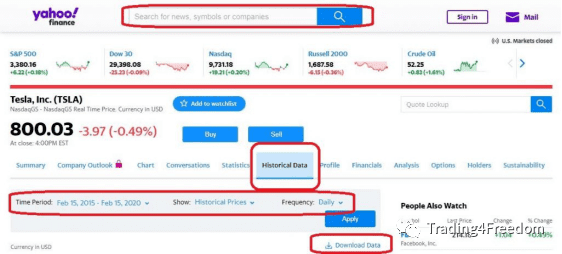
导航到Yahoo Finance 网站,输入代码或公司名称查找所需的数据。单击“历史数据”选项卡,选择起止时间段,然后单击“Apply”,将下载CSV文件保存到本地硬盘。最好将CSV文件复制到项目目录中。否则,将数据添加到Cerebro中时必须指定完整的路径名。这里使用专用于Yahoo Finance的数据格式的接口将数据添加到Backtrader中。
下面示例将CSV数据集分配给名为data的变量并添加到cerebro引擎中。
1 | data = bt.feeds.YahooFinanceCSVData(dataname='TSLA.csv') |
需要补充一句,虽然这里给的例子是用csv读取的原始数据,Backtrader是完美支持Pandas数据格式的,调用方式如下
1 | data = bt.feeds.PandasData(dataname=self.df, |
用户可以在Cerebro引擎的初始化和Cerebro.run()命令之间的任何时间添加数据。加载数据时还可指定其他参数。在下一个示例中,我们将进一步探讨这一点。
9.在Strategy类中输出数据
Strategy类是策略开发者在Backtrader中花费最多时间的地方。
为了更熟悉Backtrader中的Strategy类,这里将创建一个简单的脚本打印收盘价。这里,要做的第一件事是创建一个名为PrintClose的新类,其继承于Strategy类。
1 | import backtrader as bt |
上面的_init_() 函数创建了一个名为dataclose的变量记录收盘价。收盘价存储在datas[0].close中。用户可以通过引用data[0].open来轻松获得开盘价。如果使用多个数据Feed,则可以通过引用datas[1].close来访问第二个Feed,但稍后会介绍更多。
Backtrader的一个重要功能是访问历史数据。当Backtrader遍历历史数据时,可从dataclose[0]访问最新价格,还可以通过访问dataclose的负索引获取之前的数据。
例如,下面的代码检查最近的收盘价是否大于先前的收盘价。
1 | if dataclose[0] > dataclose [-1]: |
我们可以像这样通过更改索引轻松获得倒数第二个收盘价:dataclose[-2]
下一步是创建log()函数。
1 | def log(self, txt, dt=None): |
log()函数允许用户通过变量txt将所需的数据输出至屏幕。这里log()尝试从最近的数据点获取日期时间值(如果有),并打印至屏幕。
现在已经定义了log()函数,我们将定义next()函数。这是Strategy类最重要的部分,因为绝大多数代码都将在此处执行。每当Backtrader在下一个新数据点上进行迭代时,都会调用此部分。
1 | def next(self): |
上面的代码记录了四舍五入到两个小数点后的收盘价。
截至目前为止,完整的脚本如下:
1 | import backtrader as bt |
输出应如下所示:
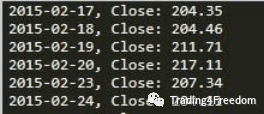
从现在开始,脚本的整体结构将基本保持不变。后续工作主要是在Strategy类的next函数下编写策略。
如何在Backtrader中进行策略回测、选股、优化、可视化以及文中案例的源码,将在下一篇给出。