在页面渲染时,我的数据是嵌套的对象,如下图: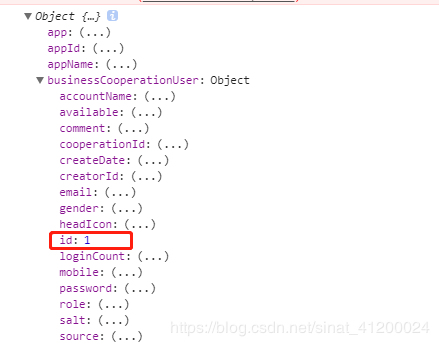
css设置背景图片模糊,内容不模糊
需求:一个div设置了background: url,现在需要使图片背景模糊,div内的文字清晰显示。
阿里云oss图片存储服务通过nginx转发至外网
公司采用了阿里云的oss来存储大量图片,oss存储很方便,存储的图片可直接通过url地址访问,但是也有个问题,外网访问oss文件需要通过流量计费,而内网访问不计流量费用。原本我们就有阿里云服务器,既然如此是否可通过在阿里云服务器上的nginx进行转发,这样就可达到即可访问oss又不需要单独计费的外网流量。
scrapy使用item,pipeline爬取数据,并且上传图片到oss
首先是要理解scrapy的运作原理是什么。这里不做解释,网上有很多资源可以理解。
用纯CSS自定义radio样式
用<label></label>标签的 for属性 + :checked 做,纯CSS